

Anxious About AI? Remember, ‘Computer’ used to be a Human Job Title…
Anxious about AI? If the thought of a machine doing your job a million times better than you scares you, read on… I recently re-watched Hidden Figures, one of my favourite movies. It hit differently this time. As someone who builds AI technology for a living, even I get anxious from time to time. What…

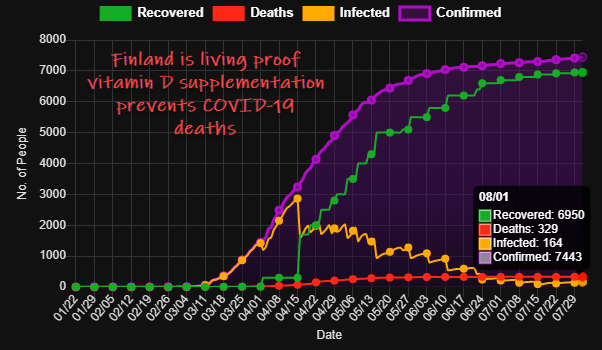
Vitamin D Prophylaxis Can End The Pandemic
We have been calling for vitamin D to be used to fight COVID19 since March – now seven months. The evidence was overwhelming then but fell on deaf ears. We published a preprint of a formal proof that vitamin D could end the pandemic six weeks later in May, urgently calling for goverments to use…
Latest Research: Vitamin D Protects Against and Treats COVID19
Four experts explain research that shows vitamin D is effective at protecting against and treating COVID19…
Are we having a second wave? Of stupidity, yes.
Are we having a second wave of COVID-19? No! We haven’t even finished the first wave yet, and a second wave – if it happens* – wouldn’t start until winter. So, why did Matt Hancock tell us we are? Because the UK government and their advisors are scientifically illiterate. * 2021 UPDATE: I was clearly…
Something went wrong. Please refresh the page and/or try again.
Get new content delivered directly to your inbox.
